library('nimble')Better block sampling in MCMC with the Automated Factor Slice Sampler
announcement
tutorial
R
One nice feature of NIMBLE’s MCMC system is that a user can easily write new samplers from R, combine them with NIMBLE’s samplers, and have them automatically compiled to C++ via the NIMBLE compiler. We’ve observed that block sampling using a simple adaptive multivariate random walk Metropolis-Hastings sampler doesn’t always work well in practice, so we decided to implement the Automated Factor Slice sampler (AFSS) of Tibbits, Groendyke, Haran, and Liechty (2014) and see how it does on a (somewhat artificial) example with severe posterior correlation problems.
Roughly speaking, the AFSS works by conducting univariate slice sampling in directions determined by the eigenvectors of the marginal posterior covariance matrix for blocks of parameters in a model. So far, we’ve found the AFSS often outperforms random walk block sampling. To compare performance, we look at MCMC efficiency, which we define for each parameter as effective sample size (ESS) divided by computation time. We define overall MCMC efficiency as the minimum MCMC efficiency of all the parameters, because one needs all parameters to be well mixed.
We’ll demonstrate the performance of the AFSS on the correlated state space model described in Turek, de Valpine, Paciorek, Anderson-Bergman, and others (2017).
Model Creation
Assume \(x_{i}\) is the latent state and \(y_{i}\) is the observation at time \(i\) for \(i=1,\ldots,100\). We define the state space model as
\[ x_{i} \sim N(a \cdot x_{i-1} + b, \sigma_{PN}) \] \[ y_{i} \sim N(x_{i}, \sigma_{OE}) \]
for \(i = 2, \ldots, 100\), with initial states
\[ x_{1} \sim N\left(\frac{b}{1-a}, \frac{\sigma_{PN}}{\sqrt{1-a^2}}\right) \] \[ y_{1} \sim N(x_{1}, \sigma_{OE}) \]
and prior distributions
\[ a \sim \text{Unif}(-0.999, 0.999) \] \[ b \sim N(0, 1000) \] \[ \sigma_{PN} \sim \text{Unif}(0, 1) \] \[ \sigma_{OE} \sim \text{Unif}(0, 1) \]
where \(N(\mu, \sigma)\) denotes a normal distribution with mean \(\mu\) and standard deviation \(\sigma\).
A file named model_SSMcorrelated.RData with the BUGS model code, data, constants, and initial values for our model can be downloaded here.
set.seed(1)
load('model_SSMcorrelated.RData')
## build and compile the model
stateSpaceModel <- nimbleModel(code = code,
data = data,
constants = constants,
inits = inits,
check = FALSE)Defining modelBuilding modelSetting data and initial valuesRunning calculate on model
[Note] Any error reports that follow may simply reflect missing values in model variables.Checking model sizes and dimensions [Note] This model is not fully initialized. This is not an error.
To see which variables are not initialized, use model$initializeInfo().
For more information on model initialization, see help(modelInitialization).C_stateSpaceModel <- compileNimble(stateSpaceModel)Compiling
[Note] This may take a minute.
[Note] Use 'showCompilerOutput = TRUE' to see C++ compilation details.Comparing two MCMC Samplers
We next compare the performance of two MCMC samplers on the state space model described above. The first sampler we consider is NIMBLE’s RW_block sampler, a Metropolis-Hastings sampler with a multivariate normal proposal distribution. This sampler has an adaptive routine that modifies the proposal covariance to look like the empirical covariance of the posterior samples of the parameters. However, as we shall see below, this proposal covariance adaptation does not lead to efficient sampling for our state space model.
We first build and compile the MCMC algorithm.
RW_mcmcConfig <- configureMCMC(stateSpaceModel)===== Monitors =====
thin = 1: a, b, sigOE, sigPN
===== Samplers =====
RW sampler (3)
- a
- sigPN
- sigOE
conjugate sampler (101)
- b
- x[] (100 elements)RW_mcmcConfig$removeSamplers(c('a', 'b', 'sigOE', 'sigPN'))
RW_mcmcConfig$addSampler(target = c('a', 'b', 'sigOE', 'sigPN'), type = 'RW_block') [Note] Assigning an RW_block sampler to nodes with very different scales can result in low MCMC efficiency. If all nodes assigned to RW_block are not on a similar scale, we recommend providing an informed value for the "propCov" control list argument, or using the "barker" sampler instead.RW_mcmc <- buildMCMC(RW_mcmcConfig)
C_RW_mcmc <- compileNimble(RW_mcmc, project = stateSpaceModel)Compiling
[Note] This may take a minute.
[Note] Use 'showCompilerOutput = TRUE' to see C++ compilation details.We next run the compiled MCMC algorithm for 10,000 iterations, recording the overall MCMC efficiency from the posterior output. The overall efficiency here is defined as \(\min(\frac{ESS}{T})\), where ESS denotes the effective sample size, and \(T\) the total run-time of the sampling algorithm. The minimum is taken over all parameters that were sampled. We repeat this process 5 times to get a very rough idea of the average minimum efficiency for this combination of model and sampler.
library(coda)
Attaching package: 'coda'The following object is masked _by_ '.GlobalEnv':
densplotRW_minEfficiency <- numeric(5)
for(i in 1:5){
runTime <- system.time(C_RW_mcmc$run(50000, progressBar = FALSE))['elapsed']
RW_mcmcOutput <- as.mcmc(as.matrix(C_RW_mcmc$mvSamples))
RW_minEfficiency[i] <- min(effectiveSize(RW_mcmcOutput)/runTime)
}
summary(RW_minEfficiency) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2679 0.3482 0.4693 0.5713 0.5903 1.1809 Examining a trace plot of the output below, we see that the \(a\) and \(b\) parameters are mixing especially poorly.
plot(RW_mcmcOutput, density = FALSE)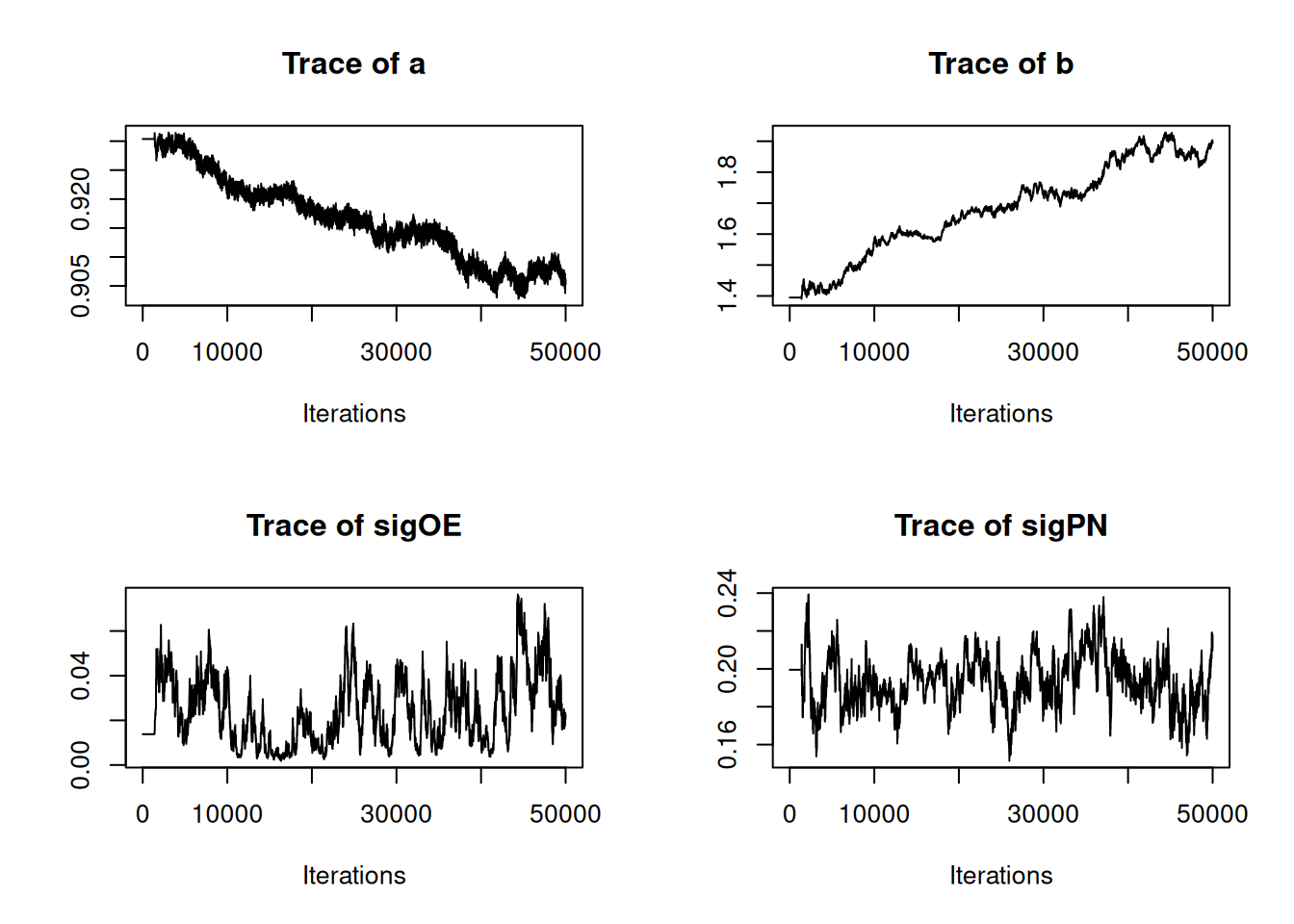
Plotting the posterior samples of \(a\) against those of \(b\) reveals a strong negative correlation. This presents a problem for the Metropolis-Hastings sampler — we have found that adaptive algorithms used to tune the proposal covariance are often slow to reach a covariance that performs well for blocks of strongly correlated parameters.
plot.default(RW_mcmcOutput[,'a'], RW_mcmcOutput[,'b'])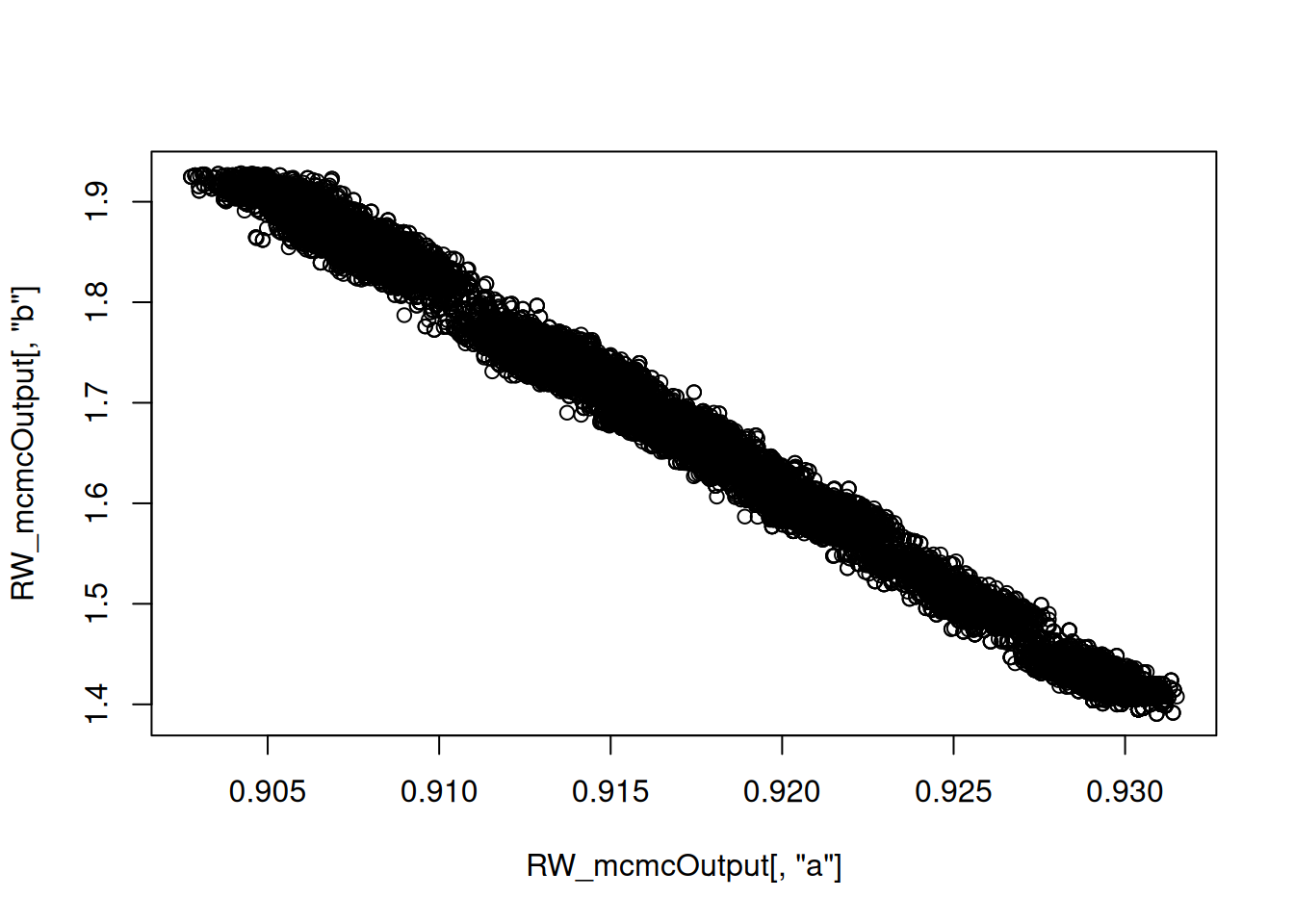
cor(RW_mcmcOutput[,'a'], RW_mcmcOutput[,'b'])[1] -0.9964729In such situations with strong posterior correlation, we’ve found the AFSS to often run much more efficiently, so we next build and compile an MCMC algorithm using the AFSS sampler. Our hope is that the AFSS sampler will be better able to to produce efficient samples in the face of high posterior correlation.
AFSS_mcmcConfig <- configureMCMC(stateSpaceModel)===== Monitors =====
thin = 1: a, b, sigOE, sigPN
===== Samplers =====
RW sampler (3)
- a
- sigPN
- sigOE
conjugate sampler (101)
- b
- x[] (100 elements)AFSS_mcmcConfig$removeSamplers(c('a', 'b', 'sigOE', 'sigPN'))
AFSS_mcmcConfig$addSampler(target = c('a', 'b', 'sigOE', 'sigPN'), type = 'AF_slice')
AFSS_mcmc<- buildMCMC(AFSS_mcmcConfig)
C_AFSS_mcmc <- compileNimble(AFSS_mcmc, project = stateSpaceModel, resetFunctions = TRUE)Compiling
[Note] This may take a minute.
[Note] Use 'showCompilerOutput = TRUE' to see C++ compilation details.We again run the AFSS MCMC algorithm 5 times, each with 10,000 MCMC iterations.
AFSS_minEfficiency <- numeric(5)
for(i in 1:5){
runTime <- system.time(C_AFSS_mcmc$run(50000, progressBar = FALSE))['elapsed']
AFSS_mcmcOutput <- as.mcmc(as.matrix(C_AFSS_mcmc$mvSamples))
AFSS_minEfficiency[i] <- min(effectiveSize(AFSS_mcmcOutput)/runTime)
}
summary(AFSS_minEfficiency) Min. 1st Qu. Median Mean 3rd Qu. Max.
23.94 25.77 30.75 29.95 31.56 37.71 Note that the minimum overall efficiency of the AFSS sampler is approximately 28 times that of the RW_block sampler. Additionally, trace plots from the output of the AFSS sampler show that the \(a\) and \(b\) parameters are mixing much more effectively than they were under the RW_block sampler.
plot(AFSS_mcmcOutput, density = FALSE)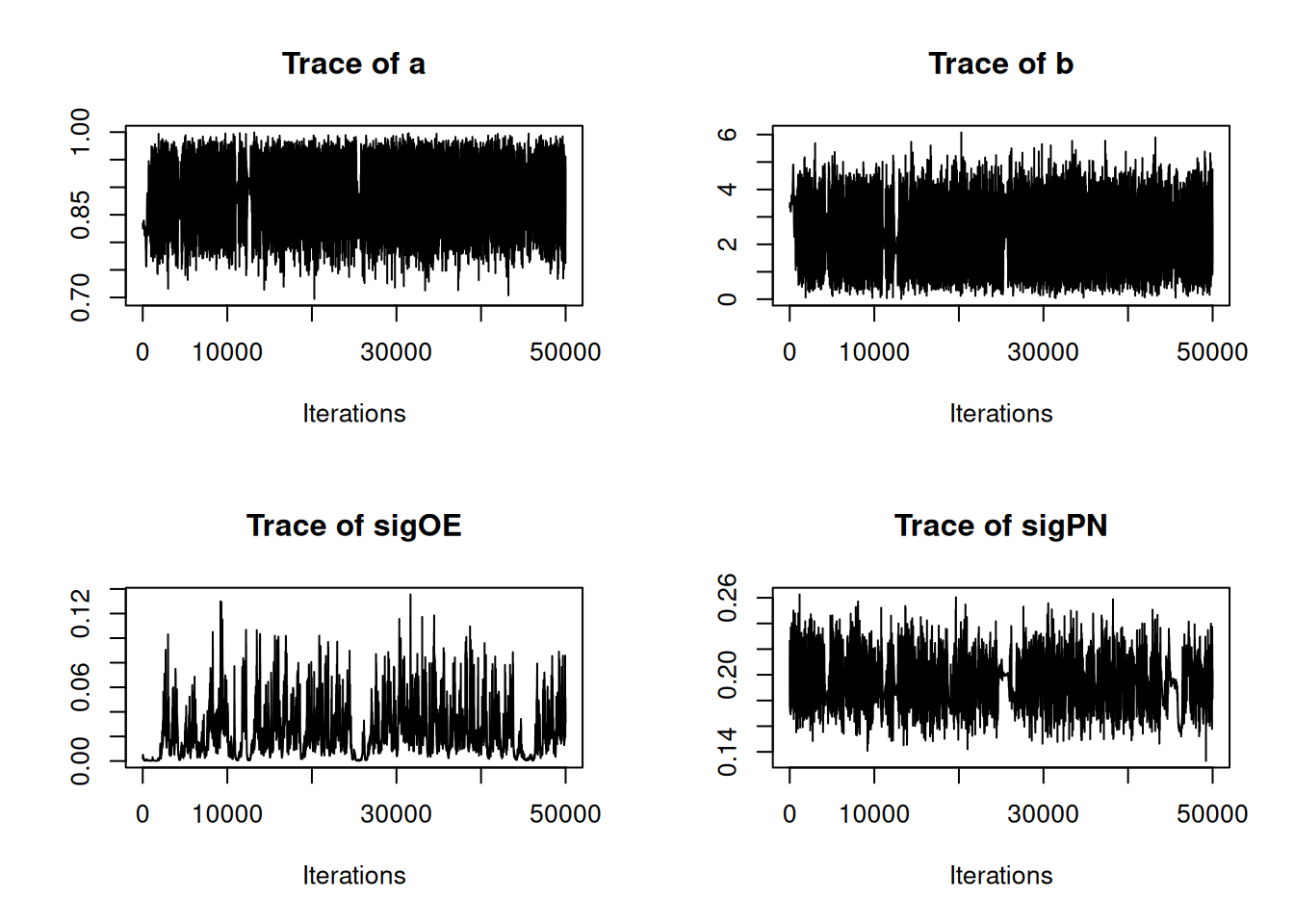
Tibbits, M. M, C. Groendyke, M. Haran, et al. (2014). “Automated factor slice sampling”.
In: Journal of Computational and Graphical Statistics 23.2, pp. 543–563.
Turek, D, P. de Valpine, C. J. Paciorek, et al. (2017).
“Automated parameter blocking for efficient Markov chain Monte Carlo sampling”.
In: Bayesian Analysis 12.2, pp. 465–490.