Home
What is NIMBLE?
Examples
Documentation
Download
Community
Blog
All Posts
Recent Posts
Version 1.4.1 Released
Using nimbleQuad for maximum likelihood estimation and deterministic posterior approximation
Using derived quantities in NIMBLE’s MCMC system
Version 1.4.0 and nimbleQuad Released
nimbleMacros Package
More
How to Contribute
Release Notes
License and Citation
About Us
Recent Posts
Recent Posts
Blog Posts
All Posts
Recent Posts
Version 1.4.1 of NIMBLE released
Using nimbleQuad for maximum likelihood estimation and deterministic posterior approximation
Using derived quantities in NIMBLE’s MCMC system
Version 1.4.0 of NIMBLE released, plus new quadrature-based functionality in nimbleQuad package
announcing the nimbleMacros package and the use of macros in NIMBLE models
Categories
All
(78)
announcement
(70)
education
(12)
R
(71)
release
(41)
tutorial
(12)
Stay up to date with the latest NIMBLE developments, releases, and community news.
Blog Posts
Welcome to the NIMBLE blog! Here you’ll find announcements about new releases, tutorials, and insights into using NIMBLE for your statistical computing needs.
Version 1.4.1 of NIMBLE released
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Feb 18, 2026
NIMBLE Development Team
Using nimbleQuad for maximum likelihood estimation and deterministic posterior approximation
R
tutorial
The new
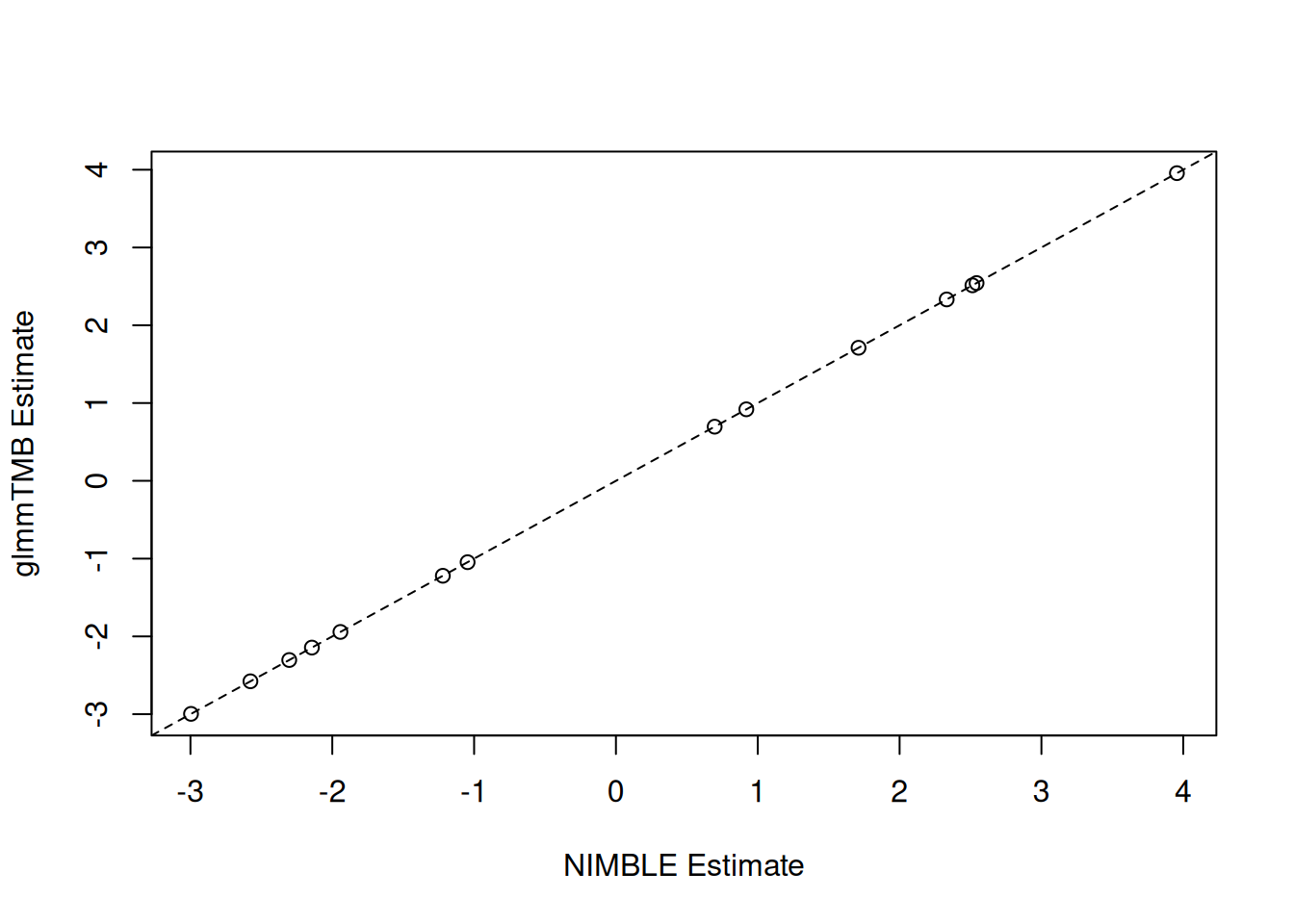
nimbleQuad
package provides quadrature-based inference methods that use Laplace and Adaptive Gauss-Hermite Quadrature (AGHQ) approximation. It has two main components:
Jan 29, 2026
Paul van Dam-Bates and Christopher Paciorek
Using derived quantities in NIMBLE’s MCMC system
announcement
R
tutorial
NIMBLE is a system for building and sharing analysis methods for statistical models, especially for hierarchical models and computationally-intensive methods (such as MCMC…
Jan 27, 2026
NIMBLE Development Team
Version 1.4.0 of NIMBLE released, plus new quadrature-based functionality in nimbleQuad package
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Jan 14, 2026
NIMBLE Development Team
announcing the nimbleMacros package and the use of macros in NIMBLE models
announcement
release
R
Recent versions of NIMBLE now include the ability to use macros in models. NIMBLE is a system for building and sharing analysis methods for statistical models, especially…
Mar 19, 2025
NIMBLE Development Team
Version 1.3.0 of NIMBLE released
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Dec 21, 2024
NIMBLE Development Team
Version 1.2.1 of NIMBLE released
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Jul 31, 2024
NIMBLE Development Team
Version 1.2.0 of NIMBLE released
release
announcement
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Jun 14, 2024
NIMBLE Development Team
Version 1.1.0 of NIMBLE released
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Feb 4, 2024
NIMBLE Development Team
nimbleHMC version 0.2.0 released, providing improved HMC performance
release
announcement
R
nimbleHMC provides Hamiltonian Monte Carlo samplers for use with NIMBLE, in particular NUTS samplers. NIMBLE’s HMC samplers can be flexibly assigned to a subset of model…
Sep 20, 2023
NIMBLE Development Team
Version 1.0.1 of NIMBLE released, fixing a bug in version 1.0.0 affecting certain models
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Jun 21, 2023
NIMBLE Development Team
Version 1.0.0 of NIMBLE released, providing automatic differentiation, Laplace approximation, and HMC sampling
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
May 31, 2023
NIMBLE Development Team
Version 0.13.1 of NIMBLE released
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. This version is purely a bug fix release that fixes a bug introduced in our new handling of…
Dec 19, 2022
NIMBLE Development Team
Bug in newly-released version 0.13.0 affecting MCMC for models with predictive nodes
announcement
R
We recently released version 0.13.0, which has some improvements in how we handle predictive nodes in NIMBLE’s MCMC engine.
Dec 8, 2022
NIMBLE Development Team
Version 0.13.0 of NIMBLE released
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Nov 29, 2022
NIMBLE Development Team
We’re looking for a programmer
announcement
R
The NIMBLE project anticipates having some funding for a part-time programmer to implement statistical algorithms and make improvements in nimble’s core code. Examples may…
Oct 7, 2022
NIMBLE Development Team
NIMBLE virtual short course, January 4-6, 2023
education
announcement
R
We’ll be holding a virtual training workshop on NIMBLE, January 4-6, 2023 from 8 am to 1 pm US Pacific (California) time each day. NIMBLE is a system for building and…
Sep 8, 2022
NIMBLE Development Team
Beta version of NIMBLE with automatic differentiation, including HMC sampling and Laplace approximation
announcement
release
R
We’re excited to announce that NIMBLE now supports automatic differentiation (AD), also known as algorithmic differentiation, in a beta version available on our website. In…
Jul 15, 2022
NIMBLE Development Team
Version 0.12.2 of NIMBLE released, including an important bug fix for some models using Bayesian nonparametrics with the dCRP distribution
release
announcement
R
We’ve released the newest version of NIMBLE on CRAN and on our website. NIMBLE is a system for building and sharing analysis methods for statistical models, especially for…
Mar 4, 2022
NIMBLE Development Team
No matching items